
Biography
I am a prospective Ph.D. student (starting Fall 2026) jointly at the College of Computer Science and Artificial Intelligence, Fudan University, and the Shanghai Innovation Institute, advised by Prof. Xipeng Qiu. Currently, I am a senior undergraduate student at Harbin Institute of Technology.
I am broadly interested in Natural Language Processing and Machine Learning. My current research focuses on Reinforcement Learning, Self-Evolving Agent and Synthetic Data Generation. I am particularly interested in leveraging reinforcement learning and its derivative techniques to stimulate the self-evolving capabilities of LLM-based agents in real-world environments.
If you are interested in any form of academic collaboration, please feel free to email me at mzli@ir.hit.edu.cn.
News
- 2025.08: 🔥 Started my internship at Shanghai Innovation Institute.
- 2025.03: 🎉 One paper “Self-Foveate: Enhancing Diversity and Difficulty of Synthesized Instructions from Unsupervised Text via Multi-Level Foveation” is accepted by Findings of ACL 2025.
Publications
♠ Innovator
♠ Data Synthesis
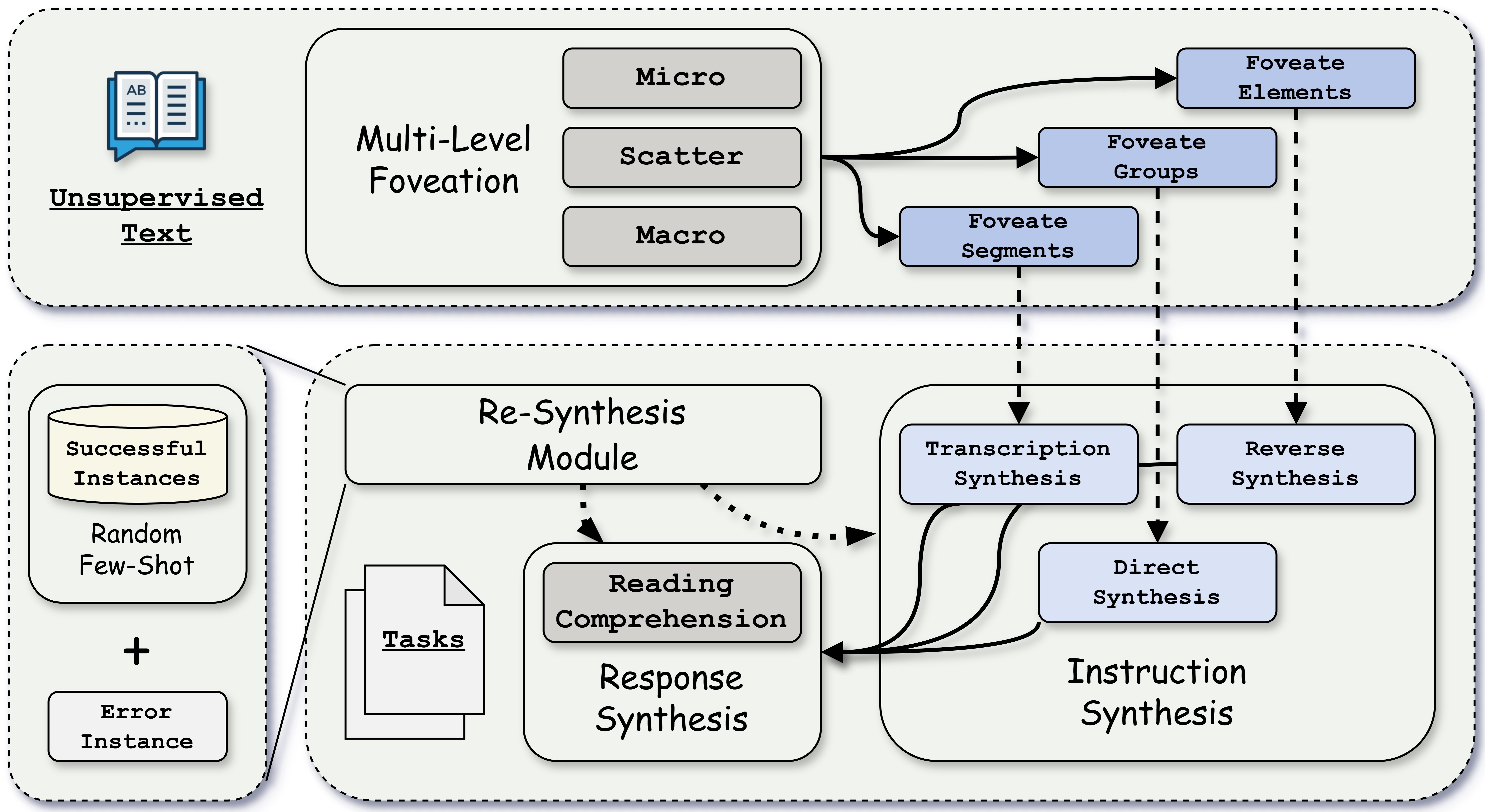
Self-Foveate: Enhancing Diversity and Difficulty of Synthesized Instructions from Unsupervised Text via Multi-Level Foveation, Mingzhe Li†, Xin Lu, Yanyan Zhao.

- Proposes an automated LLM-driven framework named Self-Foveate for instruction synthesis from unsupervised text.
- Introduces a “Micro-Scatter-Macro” multi-level foveation methodology guiding LLMs to extract fine-grained and diverse information.
- Demonstrates superior performance across multiple unsupervised corpora and model architectures.
♠ Multimodal
Thinking with Video: Video Generation as a Promising Multimodal Reasoning Paradigm, Jingqi Tong*, Yurong Mou*, Hangcheng Li*, Mingzhe Li*, Yongzhuo Yang*, Ming Zhang, Qiguang Chen, Tianyi Liang, Xiaomeng Hu, Yining Zheng, Xinchi Chen, Jun Zhao, Xuanjing Huang, Xipeng Qiu.

- Introduces “Thinking with Video”, a new paradigm unifying visual and textual reasoning through video generation models.
- Develops VideoThinkBench, a reasoning benchmark for video generation models covering both vision-centric and text-centric tasks.
- Demonstrates that Sora-2 surpasses SOTA VLMs on several tasks.
Honors and Awards
- 2025.01: Top Ten Outstanding Learning Stars of Harbin Institute of Technology (nominee).
- 2023.12: Outstanding Student of General Higher Education Institutions in Heilongjiang Province.
Educations
- 2026.09 - 2031.07 (Expected), Ph.D. student in Computer Science and Technology, Fudan University (Jointly with Shanghai Innovation Institute), Shanghai.
- 2022.08 - 2026.07, B.S. in Artificial Intelligence, Harbin Institute of Technology, Harbin.
Academic Services
- Conference Reviewer: ACL, CVPR.